Machine learning continues to expand its influence across scientific instrumentation, industrial automation, and real-time control. But while neural networks are often associated with large GPU clusters and cloud training pipelines, the story is very different when you want real-time inference, especially when signals are streaming at high bandwidth and decisions must be made with deterministic timing.
In these scenarios, the choice of hardware matters just as much as the model architecture. CPUs, GPUs, and FPGAs all offer distinct strengths, but only one platform consistently delivers ultra-low latency and cycle-accurate determinism: the FPGA.
In this article, we compare neural-network inference on CPUs, GPUs, and FPGAs, and explain how an FPGA-based implementation can achieve high-speed, real-time performance. Model training occurs in Python, outside the Moku Neural Network instrument. Once trained, you upload the model parameters to the device, where they run on the FPGA for fast, deterministic inference.

CPUs: Flexible and accessible, but not real-time
CPUs remain the most widely used compute platform for smaller neural networks because they’re easy to program and already present in every system. They provide flexible general-purpose compute and are great for experimenting or training small models.
However, CPUs struggle with real-time workloads because they lack deep parallelism and have variable latency from one inference to the next. CPUs are also limited in how efficiently they can connect to high-speed analog or digital I/O.
GPUs: Outstanding throughput, but not deterministic
GPUs dominate the world of AI training thanks to their massively parallel architecture. They are exceptional for accelerating matrix operations and training large models.
But for high-speed real-time inference, GPUs face inherent architectural limitations:
- Data must be shuttled between CPU memory and GPU memory.
- GPUs are optimized for batch processing, not low-latency single-sample inference.
- They consume significant power and require active cooling.
- Real-time integration with sensors requires additional hardware.
FPGAs: Built for deterministic, low-latency execution
FPGAs provide a fundamentally different compute model. Instead of executing instructions sequentially, they allow complete hardware pipelines that process data in a streaming, parallel fashion. Every neuron or layer can be mapped to dedicated logic.
For real-time systems, FPGAs offer:
- Cycle-accurate timing, where each inference always takes the same number of clock cycles.
- Ultra-low latency data flows through hardware pipelines.
- True parallelism where layers operate simultaneously, not sequentially.
- Power efficiency through spatial computing.
- Direct interface to ADCs, DACs, and sensor I/O without OS or driver overhead.
These characteristics make the FPGA the ideal platform for real-time neural-network inference.
Why real-time neural networks need FPGAs
Real-time constraints
In many scientific and engineering systems such as experiment control, manufacturing test, adaptive filtering, and quantum or optical feedback, latency must be not just low but predictable.
An FPGA ensures pure hardware timing, without:
- Jitter
- Cache misses
- Unpredictable kernel delays
Determinism vs. “best effort” computation
CPUs and GPUs operate on best-effort timing: performance varies based on system load, temperature, or memory traffic. For machine learning tasks like training or cloud inference, this is acceptable. For a real-time control loop, it isn’t.
FPGAs provide deterministic execution by physically structuring the logic for the task. This results in identical latency every time.
Maximizing throughput at low power
An FPGA’s spatial architecture allows parallel compute at moderate clocks, leading to:
- High inference rates
- Lower power draw than a GPU
- Stable thermal behavior
- Predictable energy consumption
This is ideal for embedded applications and lab instruments.
How Moku implements neural network inference
Liquid Instruments’ Moku Neural Network brings FPGA-accelerated inference to scientists and engineers without requiring any HDL, hardware design experience, or FPGA toolchains. The process is simple, fast, and accessible.
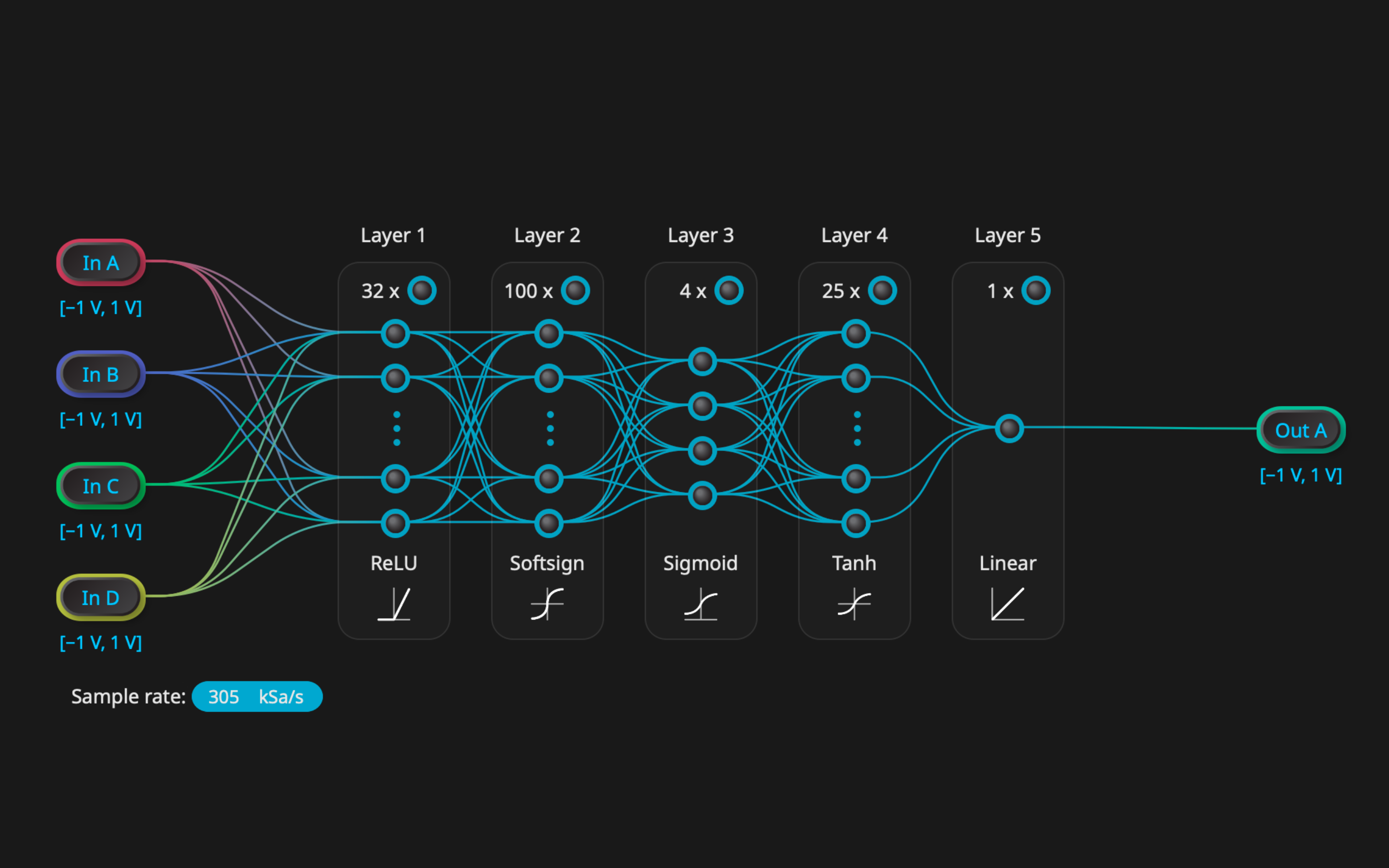
1. Train in Python
Models are designed and trained using standard machine learning libraries such as PyTorch or TensorFlow. Training happens offline, on a CPU or GPU.
2. Export and convert the model
Using the Moku Python tools, you convert your trained network into a hardware-ready format. This includes:
- Quantization
- Layer mapping
- Parameter formatting
The toolchain handles all FPGA specifics behind the scenes.
3. Upload to Moku
The trained weights and network configuration are uploaded to the Moku instrument using the API or GUI.
4. Real-time inference on the FPGA
Once deployed, the FPGA executes the neural network as a fully pipelined hardware circuit, enabling:
- Continuous streaming inference
- Low-latency feedback
- Tight integration with Moku’s other instruments
- Deterministic, real-time operation
Because the model is static, the Moku dedicates all resources to inference, ensuring maximum reliability and speed.
Real-time FPGA inference application examples
Real-time experiment control
Applications such as optical cavity locking, interferometry, atomic sensing, or qubit state classification require microsecond (or faster) decision-making. This is where FPGA inference far outperforms CPU and GPU systems.
Manufacturing test and embedded automation
Neural networks can classify transients, detect anomalies, or guide automated processes at line speed. FPGA-based inference eliminates PC-based latency and jitter.
High-speed signal processing
Where traditional DSP blocks may fall short, neural networks can approximate complex nonlinear relationships while still running at MHz-level sample rates.
How Moku makes FPGA inference easy
Traditionally, FPGA-based neural networks required HDL coding, vendor-specific tools, and hardware expertise. Moku eliminates these barriers with:
- A Python-based training-to-deployment workflow
- Automatic quantization and hardware mapping
- A unified instrument ecosystem for analog/digital I/O
- Real-time visualization and control in the Moku app
- Seamless integration with other tools like oscilloscopes, AWGs, filters, and PID controllers
Conclusion
CPUs and GPUs are excellent training platforms, but when it comes to real-time inference, their latency, jitter, and architectural overhead make them unsuitable for high-speed, deterministic applications.
FPGAs, by contrast, offer:
- Predictable cycle-accurate timing
- Ultra-low latency
- Parallelized hardware execution
- Direct sensor and I/O integration
- Efficient, continuous, streaming computation
Liquid Instruments’ Moku Neural Network brings these advantages to scientists and engineers in a user-friendly, Python-driven workflow. By combining FPGA performance with intuitive tools, Moku enables a new class of intelligent, real-time instrumentation that was previously out of reach for most developers.